
URL Classification
Analytical Approaches and Justification
Overview
- Task: Analyze data from PhishTank to assist with classifying URLs as malicious.
- Value: Being able to identify the maliciousness of URLs can save individuals and organizations from making extremely costly mistakes.
- Companies can use this intelligence to flag URLs as risky.
- While it is ultimately up to the user to determine if they click a link, being able to provide a potential warning is extremely valuable.
- Potential Value: Identifying specific features from the URLs (ex: number of symbols/digits/etc.) to see if they can assist with accuracy of predictions.
Data Additions
- The current dataset contains approximately 8,000 malicious URLs.
- With the end goal being to classify if a URL is malicious, additional data needs to be added with valid/safe URLs to help train the model.
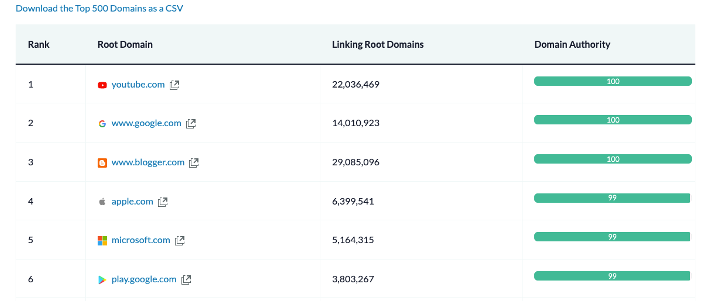
- Moz.com provides a CSV of some of the most popular websites.
- The dataset is limited to 500 records.
Feature Limitations
- The data provided by PhishTank is very valuable; however, it lacks detailed information.
- Two of the provided columns include "verified" and "online" but they will always be "yes" for our data set due to the nature of PhishTank's file.
- While the "target" column has a handful of records relating to the financial industry, the vast majority is classified as "Other".

Feature Additions
- To assist with the classification model, pre-processing was performed on the data to provide additional features.
- The following columns were added to the dataset:
- is_malicious = Indicates if a URL is malicious
- length = Length of the URL
- num_digits = Number of digits in the URL
- has_digits = Indicates if the URL has digits
- num_symbols = Number of symbols in the URL
- has_symbols = Indicates if the URL has symbols
Final Dataset
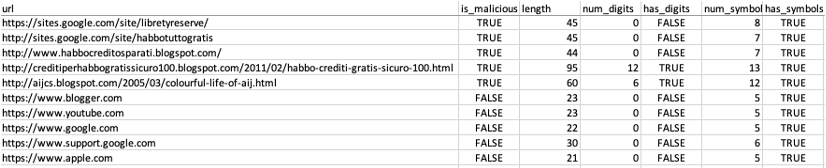
- After the pre-processing, the final dataset includes a combination of 500 safe URLs and approximately 8,000 malicious URLs.
- The attributes in the dataset are:
- url
- is_malicious
- length
- num_digits
- has_digits
- num_symbols
- has_symbols
Process
- Step 1 : Gather PhishTank data from CSV file stored in S3 Bucket
- Step 2 : Gather Safe URL data from CSV file provided by Moz.com
- Step 3 : Combine datasets into a single CSV file
- Step 4 : Pre-process the data to identify additional features (ex: malicious, number of symbols/digits, etc.)
- Step 5 : Pass the dataset through a Random Forest algorithm in WEKA to test the predictive abilities of classifying URLs as malicious and the overall accuracy of the model
Key Insights and Intelligence
Overview
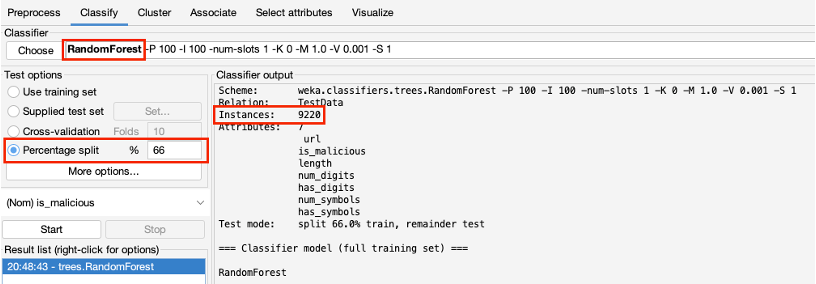
- To assist with classification, the Random Forest algorithm was used on the datasets. WEKA was used as the software tool to execute the process.
- The dataset contains 9,220 instances (URLs).
- 66% of the dataset was used for training and the remainder was used to test the model.
Initial Results
- Prior to performing any pre-processing, the initial dataset was passed through a Random Forest to see how it would perform with fewer attributes.
- For this analysis, the two attributes were:
- url
- is_malicious
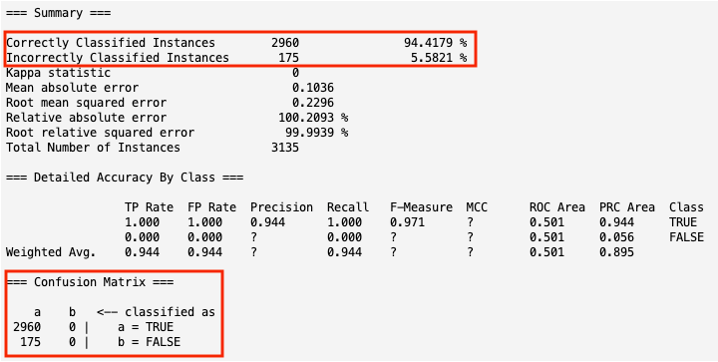
- From the initial passthrough, the model correctly classified 94.4179% of the URLs as malicious or not.
- Of the 3,135 instances tested, 2,960 of the instances were correctly classified as malicious while 175 instances were incorrectly classified as not malicious when they were malicious (false positives).
Pre-Processing Results
- After testing the precision of the initial dataset with 2 attributes, the full/final dataset was used with all 7 attributes.
- With the additional features included that outline specific characteristics of the URLs, the hope/expectation is that the classification model will have a better likelihood of correctly classifying the URLs.
- With more attributes, the model was significantly more precise and correctly classified 99.0431% of the URLs as malicious or not.
- Of the 3,135 instances tested, 2,960 of the instances were correctly classified while 30 instances were incorrectly classified as not malicious when they were malicious (false positives).
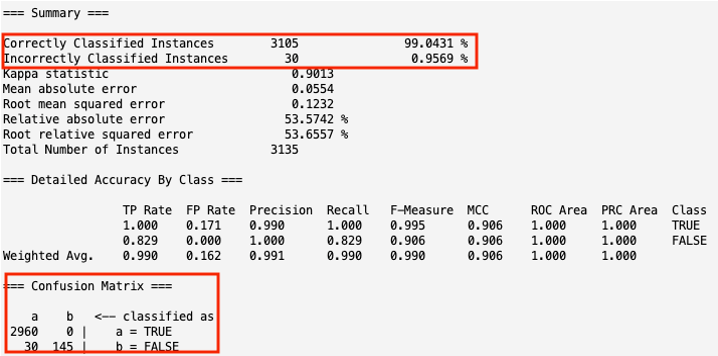
Smaller Dataset
- While the model was significantly more precise with additional features, the ratio of safe URLs to malicious URLs was about 500 to 8000, or 1:16. This could potentially skew the results due to class imbalance.
- Our Team wanted to test the effectiveness of adjusting the overall dataset (with 7 attributes) to a closer ratio.
- As Moz.com only provides the top 500 URLs, the data from PhishTank was reduced to 1,000 URLs.
- The count of records in the new dataset was 1,500:
- 2/3 (1,000) of the URLs are malicious.
- 1/3 (500) of the URLs are not malicious.
- With a smaller dataset and closer ratio, the model correctly classified 100% of the URLs as malicious or not.
- All 510 instances tested were correctly classified:
- 346 instances were correctly classified as malicious URLs.
- 164 instances were correctly classified as non-malicious URLs.
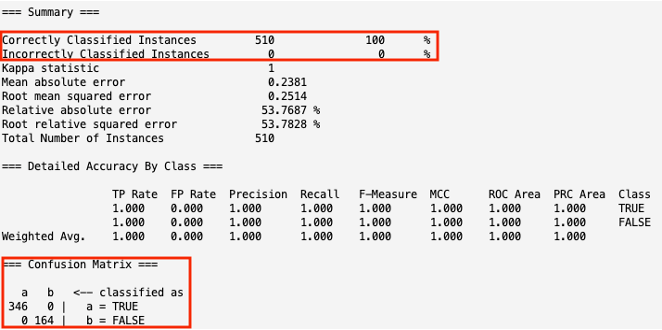
Key Takeaways
- While phishing is one of the largest threats to the financial industry, it also remains a threat to other industries. Although the dataset was more general (vs. a specific industry), the intelligence gathered from this analysis can be applied and provide value to the financial industry.
- Looking at additional characteristics of a URL can help with identifying if they are malicious.
- Malicious URLs averaged a length of ~52.94 characters, ~4.55 digits, and ~8.51 symbols.
- Non-malicious URLs averaged a length of ~11.47 characters, 0.02 digits, and ~1.22 symbols (see next slide for observation).
- Having a dataset with a closer balance of classes helps the classification model be more precise.